Code Review Bottlenecks in the AI Era
AI coding tools cut development time in half. But if reviews stack up, delivery doesn't get faster. Here's how to identify and fix the bottlenecks that neutralize your AI productivity gains.
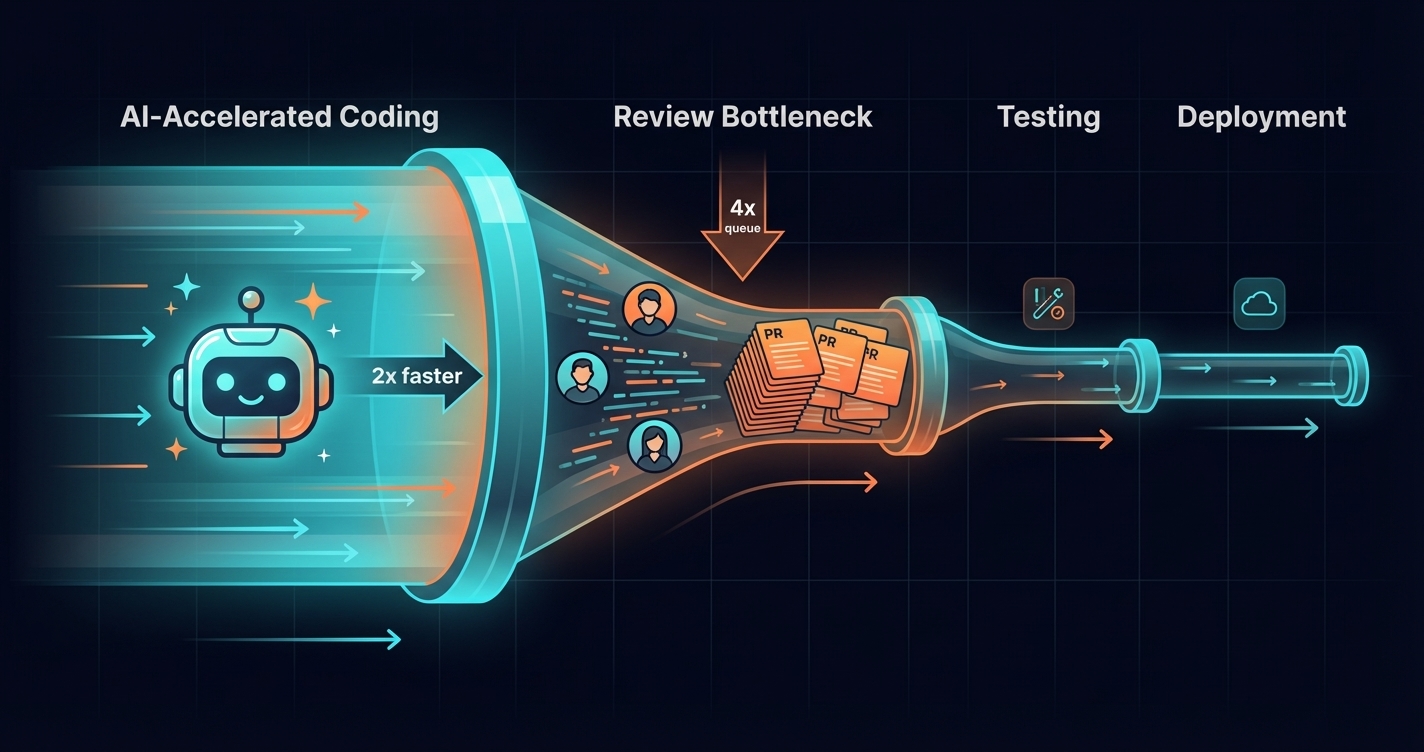
Your team adopted GitHub Copilot six months ago. Developers love it. They’re writing code faster than ever. Your internal surveys show 60% of engineers report significant productivity improvements.
But when you look at your delivery metrics, something strange is happening: lead time hasn’t improved. In fact, it might have gotten slightly worse.
What’s going on?
You’ve hit the bottleneck displacement problem. AI accelerated one part of your pipeline—writing code—but the bottleneck simply moved downstream. Now code reviews are the constraint, and no amount of faster coding will improve delivery until you address it.
This pattern is so common that the 2025 DORA report explicitly warns about it. AI doesn’t eliminate bottlenecks—it reveals them.
The Bottleneck Displacement Phenomenon
Think about your development pipeline as a series of stages:
Coding → Code Review → Testing → DeploymentBefore AI tools, coding was often the longest stage. A feature that took 8 hours to code, 2 hours to review, 1 hour to test, and 30 minutes to deploy had coding as the constraint.
Now add AI assistance. Coding time drops to 4 hours. Great! But the pipeline now looks like:
Before AI: Coding (8h) → Review (2h) → Testing (1h) → Deploy (0.5h)
After AI: Coding (4h) → Review (4h) → Testing (2h) → Deploy (0.5h)Wait—why did review and testing time increase?
Because there’s more code being produced. The same reviewer who handled 3 PRs per day now has 6 in their queue. The test suite that ran for an hour now runs against twice as many changes. The bottleneck didn’t disappear—it moved.
The DORA Research Confirms This
Faros AI’s analysis of the 2025 DORA data found what they call the “AI Productivity Paradox”: developers using AI tools completed 21% more tasks and merged 98% more pull requests, but organizational delivery performance didn’t improve correspondingly.
The insight: when your deployment pipeline is held together with manual processes, when your review cycles are capacity-constrained, when your test suite is flaky or slow—generating more code faster just exacerbates bottlenecks elsewhere.
AI is an amplifier. If your pipeline had hidden constraints, AI makes them visible by pushing more work into them.
Identifying Your Review Bottlenecks
Before you can fix bottlenecks, you need to find them. Here’s how to diagnose where time accumulates in your review process.
Metric 1: Time to First Review
How long does a PR sit before someone looks at it?
| Time to First Review | Interpretation |
|---|---|
| < 2 hours | Healthy—reviews are prioritised |
| 2-8 hours | Acceptable—same-day reviews |
| 8-24 hours | Warning—PRs waiting overnight |
| > 24 hours | Problem—significant queue buildup |
Long time-to-first-review typically indicates:
- Reviewers are overloaded
- Reviews aren’t prioritised
- Unclear ownership of review responsibilities
- Too many PRs competing for limited reviewer attention
Metric 2: Review Rounds
How many back-and-forth cycles before merge?
| Review Rounds | Interpretation |
|---|---|
| 1 | Ideal—clean first submission |
| 2 | Normal—minor feedback incorporated |
| 3 | Concerning—significant rework needed |
| 4+ | Problem—quality issues or unclear requirements |
High review rounds can indicate:
- Unclear coding standards (reviewers catch things that should be automated)
- Requirements misunderstandings (building the wrong thing)
- Insufficient design discussion before coding
- Review feedback that’s vague or inconsistent
Metric 3: Reviewer Concentration
Are reviews distributed across the team or concentrated on a few people?
Calculate what percentage of reviews are done by your top 20% of reviewers. If it’s over 50%, you have a concentration problem. If it’s over 70%, you’re one resignation away from a crisis.
Reviewer concentration creates:
- Queue buildup when key reviewers are busy
- Knowledge siloing (only certain people understand certain code)
- Burnout for overloaded reviewers
- Single points of failure
Metric 4: Review Depth
Are reviewers doing thorough reviews or rubber-stamping?
Look at:
- Comment frequency per PR
- Comment length and substance
- Time spent in review (if measurable)
- Bug escape rate for reviewed code
Shallow reviews move fast but miss problems. If your reviews are quick but your production bugs are increasing, you may be trading review time for debugging time.
Metric 5: PR Size
Larger PRs take longer to review and have more issues. Track:
- Average lines changed per PR
- Distribution of PR sizes (are some huge while most are small?)
- Correlation between PR size and review time
Google’s research suggests PRs under 200 lines get reviewed 3x faster than PRs over 500 lines. In the AI era, it’s easy to generate large PRs quickly—but they create downstream review burden.
Why AI Makes Review Harder
AI coding tools don’t just produce more code—they produce different code that presents unique review challenges.
Challenge 1: Volume
The most obvious challenge: more PRs to review. If developers can write code twice as fast, and you don’t change anything else, your review queue doubles.
But it’s not just volume—it’s the pattern of volume. AI-assisted developers often submit more, smaller PRs throughout the day rather than one large PR at the end. This can be good (smaller PRs are easier to review) or bad (context switching for reviewers).
Challenge 2: Unfamiliarity
AI generates code the human developer didn’t write line-by-line. This creates a disconnect:
- The developer may not fully understand the generated code’s nuances
- They may not catch subtle issues before submitting
- The PR description may not accurately reflect implementation details
- Questions about “why did you do it this way?” may be harder to answer
Reviewers need to be more thorough, not less, when reviewing AI-assisted code.
Challenge 3: Quality Variance
AI-generated code quality is inconsistent. It can be:
- Perfectly correct and idiomatic
- Correct but verbose or unidiomatic
- Subtly wrong in edge cases while passing tests
- Completely wrong but plausible-looking
The 2025 DORA report found that 30% of developers don’t trust AI-generated code. This skepticism is warranted—AI code requires careful review, but review fatigue makes careful review harder.
Challenge 4: Test Coverage Gaps
AI often generates code that passes existing tests but doesn’t handle edge cases. If your test suite is the safety net and AI-generated code has gaps in areas not covered by tests, reviews become the last line of defense.
This puts more pressure on reviewers to catch things that tests should catch.
Fixing Review Bottlenecks
Now that you understand where bottlenecks form, here’s how to address them.
Strategy 1: Reduce Review Load Through Automation
Before humans review code, automation should catch everything automatable:
Linting and Formatting: Automated checks for style issues, unused imports, formatting problems. These shouldn’t consume reviewer attention.
Static Analysis: Type checking, security scanning, complexity analysis. Flag potential issues before human review.
Test Gates: PRs shouldn’t be reviewable until tests pass. Don’t waste human time reviewing code that doesn’t work.
AI Review Assistants: Tools like GitHub Copilot for Pull Requests can provide initial review feedback, highlighting potential issues for human reviewers to verify.
The goal: humans review for logic, architecture, and requirements fit—not for things machines can check.
Strategy 2: Distribute Review Load
If reviews concentrate on a few people, fix the distribution:
Explicit Review Rotation: Rather than relying on volunteers, assign review responsibility systematically. Tools like GitHub’s CODEOWNERS can automate this, but manual rotation works too.
Review Quotas: Set expectations that everyone does some percentage of reviews. Track and make visible who’s reviewing versus who’s only submitting.
Cross-Training: If certain people are bottlenecks because only they understand certain code, that’s a knowledge-sharing problem. Pair programming, documentation, and explicit knowledge transfer reduce concentration.
Load Balancing: When assigning reviewers, consider their current queue. Assign to the person with capacity, not just the person with expertise.
Strategy 3: Reduce Review Rounds
Multiple review rounds indicate problems earlier in the process:
Coding Standards Automation: If reviewers consistently flag the same issues, those issues should be caught by linters or automated checks—not human review.
Design Reviews Before Coding: For significant changes, discuss the approach before implementation. Catching misalignment before code is written is far cheaper than catching it in review.
Clear PR Templates: Require PRs to include what changed, why it changed, how to test it, and any risks. Good context enables good reviews.
Reviewer Consistency: If different reviewers flag different things, establish shared standards. Inconsistent review feedback wastes everyone’s time.
Strategy 4: Optimise PR Size
Smaller PRs are reviewed faster and more thoroughly:
Enforce Size Limits: Warn or block PRs over a certain size (300-500 lines is a common threshold). Exceptions require justification.
Encourage Stacking: Train developers to break large changes into smaller, sequential PRs that build on each other.
Separate Refactoring from Features: A PR that both adds functionality and refactors existing code is hard to review. Split them.
AI-Specific Guidance: When AI generates large blocks of code, encourage developers to submit in logical chunks rather than one massive PR.
Strategy 5: Prioritise Review
Make code review a first-class priority, not something done “when there’s time”:
Review-First Culture: Before starting new work, clear your review queue. This sounds counterintuitive but reduces overall cycle time.
Time-Boxing: Dedicate specific times for review rather than context-switching throughout the day. Morning review hour, for example.
SLAs and Visibility: Set explicit expectations for review turnaround and make queue status visible. Nothing motivates clearing a queue like visibility.
Reduce Review Friction: Make it easy to start a review. One-click checkout of PR branch, automated test environments, clear feedback mechanisms.
Strategy 6: Match AI Output to Review Capacity
If AI generates code faster than you can review it, you have options:
Increase Review Capacity: More reviewers, faster tools, better automation.
Decrease Code Output: This sounds backwards, but sometimes the right answer is to slow down. If you’re creating more code than you can quality-control, you’re not actually moving faster.
Change What AI Does: Focus AI on tasks that don’t create review burden—test generation, documentation, refactoring existing code to be clearer.
Batch and Schedule: Rather than continuous PRs throughout the day, batch AI-assisted work into reviewable chunks at predictable times.
Measuring Improvement
Once you’ve implemented changes, track whether they’re working:
Leading Indicators (Will Show Improvement First)
- Time to first review (should decrease)
- Review queue size (should stay controlled)
- Reviewer distribution (should become more even)
Lagging Indicators (Will Show Improvement Later)
- Overall lead time (should decrease as reviews stop being the constraint)
- Deployment frequency (should increase as PRs clear faster)
- Developer satisfaction with reviews (should improve)
Warning Signs of Over-Optimization
- Bug escape rate increasing (reviews may be too shallow)
- Review rounds dropping to always 1 (may indicate rubber-stamping)
- Very short review times (may not be thorough)
The goal isn’t zero review time—it’s appropriate review time that doesn’t create bottlenecks.
The Bigger Picture: Flow Efficiency
Code review bottlenecks are part of a larger question: where does time actually go in your development process?
Flow efficiency measures what percentage of total lead time is spent in value-adding work versus waiting:
Flow Efficiency = Active Work Time / Total Lead Time × 100%Most engineering organisations have flow efficiency below 15%. That means for every 8 hours of lead time, less than 75 minutes is actual work—the rest is waiting.
Review wait time is often the largest single contributor to low flow efficiency. A PR that takes 2 hours to code, sits for 6 hours awaiting review, takes 30 minutes to review, waits another 4 hours for CI, and deploys in 10 minutes has flow efficiency of about 22%.
AI makes coding faster, but it doesn’t touch the waiting time. To truly improve delivery, you need to address the entire flow—not just the parts that are already fast.
The AI Review Future
Looking ahead, AI may help solve the problems it creates:
AI-Assisted Review
Tools that automatically review code for common issues, suggest improvements, and highlight areas needing human attention. These exist today but are rapidly improving.
Predictive Quality Signals
AI that predicts which PRs are high-risk based on code patterns, author history, and change characteristics—helping humans focus review attention where it matters most.
Automated Test Generation
AI that generates tests for code it generates, reducing the test coverage gap problem and giving reviewers more confidence.
Review Summarization
AI that summarizes large PRs, explains the approach, and highlights key decision points—reducing reviewer cognitive load.
But none of these eliminate the need for human judgment. They shift human attention from mechanical checking to meaningful evaluation. The bottleneck may move again, but human review remains essential.
Key Takeaways
-
AI accelerates coding but doesn’t eliminate bottlenecks—it moves them downstream to reviews, testing, and deployment.
-
Measure where time accumulates: time to first review, review rounds, reviewer concentration, and PR size.
-
Automate what’s automatable: linting, formatting, static analysis, and test gates should handle mechanical checks.
-
Distribute review load: concentration on a few reviewers creates fragility and queues.
-
Optimise PR size: smaller PRs review faster and more thoroughly.
-
Make review a priority: it’s not overhead—it’s part of delivery.
-
Track flow efficiency: review time is one part of the larger picture of where time goes.
The teams that get the most from AI coding tools aren’t the ones that just write code faster. They’re the ones that optimise their entire delivery pipeline so faster coding translates to faster delivery.
See Where Your Time Goes
GuideMode tracks flow analytics across your entire delivery pipeline—from coding through review to deployment. Identify bottlenecks, measure improvement, and understand where AI is helping and where it’s just moving the constraint.